为什么我还是无法理解transformer?
之前答过ChatGPT的基本原理,再说下Transformer。
能大致讲一下ChatGPT的原理吗?Transformer作为一种深度学习模型架构,不是一下子提出来的,而是在前面的NLP(自然语言处理)模型的基础上,引入了改进和创新。
所以,在说Transformer之前,要先说下,这个走在Transformer前面的NLP模型架构Seq2Seq。
Seq2Seq(Sequence-to-Sequence),序列到序列模型,也是一种深度学习架构,最初在2014年由Google的研究人员提出,用于解决机器翻译问题。
在Seq2Seq之前,传统的机器翻译方法,主要依赖于统计模型和规则系统,需要大量的人工标注数据,并且难以处理复杂的语言结构。
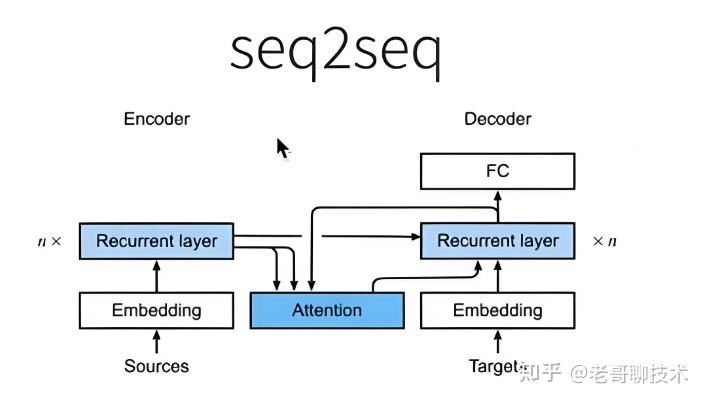
Seq2Seq模型,主要由编码器(Encoder)和解码器(Decoder)组成。
通过使用神经网络,特别是循环神经网络(RNN)及其变种(LSTM和GRU),自动学习输入序列与输出序列之间的映射关系。
编码器:读取输入序列(例如一个英文句子),将其压缩成一个固定长度的向量,称为“上下文向量”或“隐藏状态”。这个向量包含了整个输入序列的信息。
解码器:从上下文向量开始,逐步生成输出序列(例如对应的中文句子)。解码器每一步都会预测下一个词,并将该词作为下一步的输入,直到生成结束标记为止。
Seq2Seq模型,虽然不用人工标注了,也能处理较复杂的语言结构,但存在两个致命的问题。
一个是长距离依赖问题。
虽然RNN及其变种(LSTM和GRU)能够处理距离依赖,但在非常长的序列中仍然会遇到梯度消失或爆炸的问题。
一个是解码时的误差累积问题。
在解码过程中,如果某一步生成了错误的词,后续步骤可能会基于这个错误继续生成,导致整个输出质量下降。
为了解决这两个问题,Google 在 2017 年又发表了论文《Attention is All You Need》,提出了 基于自注意力机制(Self-Attention Mechanism)的Transformer模型。
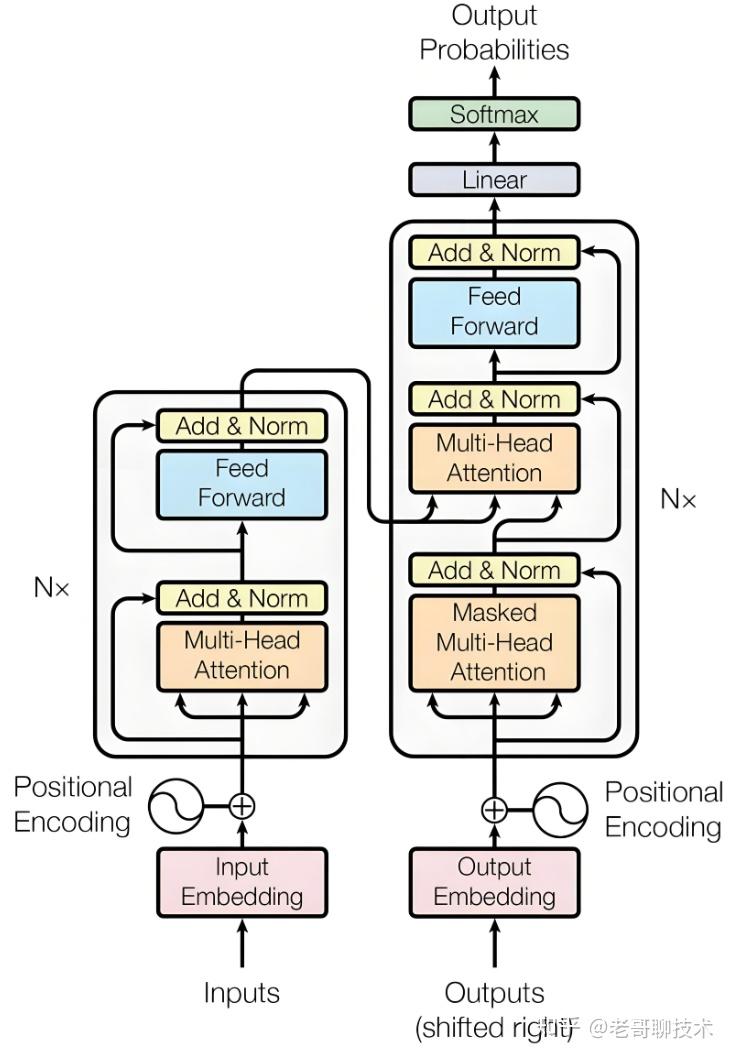
Transformer仍然是由编码器(Encoder)和解码器(Decoder)组成,原论文中的经典的架构图如下。
对应的中文版架构图如下。
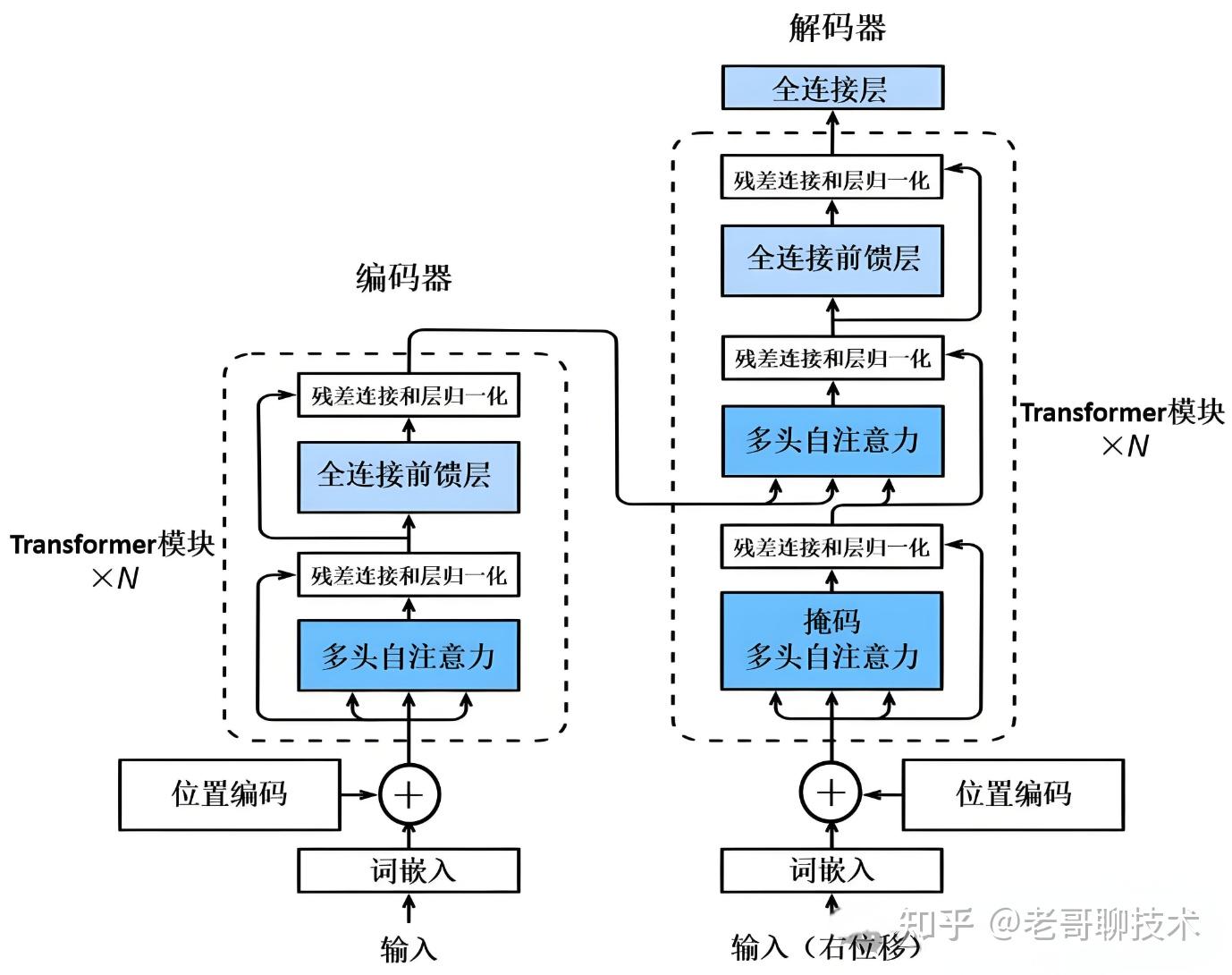
要理解transformer,其实,主要是理解这两幅架构图里的自注意力和多头注意力机制。
试着通俗的解释下上面两幅图。
编码器部分
输入嵌入(Input Embedding)
假设输入序列是“我喜欢知乎”。
首先,每个词(“我”、“喜欢”、“知乎”)都会通过一个嵌入层转换成一个高维向量。
这个过程就类似于给每个词分配了一个独一无二的“身份证”,让模型能够识别并理解它们。
位置编码(Positional Encoding)
由于Transformer模型本身不包含循环结构,无法直接理解每个输入词的顺序。
因此,需要给每个输入词的嵌入向量加上一个位置编码,以表示词在句子中的位置。
这样,模型就能区分不同位置上的相同词了。
自注意力机制(Self-Attention)
自注意力机制是Transformer的核心。
在处理某个词时,模型会同时考虑句子中所有其他词的上下文信息。
具体来说,模型会为每个词生成三个向量:查询(Query)、键(Key)和值(Value)。然后,通过计算查询向量和键向量之间的相似度(点积),得到注意力权重。
就是大部分网上资料里介绍的KVQ公式。
这些权重用于加权求和值向量,从而得到每个词的新表示,这个新表示包含了句子中所有词的上下文信息。
由于包含所有词的上下文信息,所以,基本上就解决了长距离信息依赖的问题,消除了误差信息。
多头注意力(Multi-Head Attention)
为了进一步提升模型的性能,Transformer使用了多头注意力机制。
将自注意力机制分成多个“头”,每个头独立地执行上述自注意力操作,然后将结果合并。
这样做的好处是可以让模型同时学习不同位置的不同表示子空间,从而捕捉输入数据中的多种类型的信息或模式。
从各个维度更好的理解信息。
解码器部分
解码器的工作流程与编码器类似,但多了一步对编码器输出的注意力计算。
在生成输出序列时,解码器会根据已经生成的部分和编码器的输出来预测下一个词。
具体来说,解码器中的每个词都会通过自注意力机制考虑已经生成的词,并通过编码器-解码器注意力机制考虑编码器的输出,从而生成新的表示,并且用于预测下一个词。
也就是,解码器会逐个单词地预测下一个最合适的词,直到构成一个完整的句子。
知乎专栏里有一篇讲transformer的自注意力和多头自注意力的文章,算是比较简洁的,也可以看看。
求求你们别学了:深度解析:Transformer及其在深度学习中的应用以上,完。
 新公网安备 65010402001845号
新公网安备 65010402001845号