如何看待 OpenAI 发布 o1 系列模型?将带来哪些变革?
本来都要睡了,爬起来写点东西吧
其实截止至今晚之前,OpenAI 的乏力似乎是肉眼可见,Sora 的无限期跳票,GPT4o 的演示效果也没有被很好复现,再加上宫斗后遗症以及不少人才流失,Claude/Google/xAI 等一众竞争对手也从难以望其项背追赶到似乎触手可及。
OpenAI 用一颗 证明了,你大爷暂时还是你大爷,也给本来沉闷的夏末,带来一缕清风。哦不,是一道惊雷,也震醒了最近唱衰大模型前景的人。(各位从业同学又续了一命,还不快去买英伟达股票
---- 矫情结束的分割线 ----
好了说点正经的,这次发布到底带来了哪些东西
首先是 Scaling law 范式的更新
在已经为大家熟知的 data/model size/computation 外,又多了 一条 inference time compute。虽然这个思路看起来非常顺理成章,不管是思维快与慢(System I&II),还是 long context many-shot s CoT,似乎走到这一步都是水到渠成的事,但是第一个真正把它 scale 上去的人才真的牛逼。引用Greg 的话:
People have discovered a while ago that prompting the model to “think step by step” boosts performance. But training the model to do this, end to end with trial and error, is far more reliable and — as we’ve seem with games like Go or Dota — can generate extremely impressive results.
人们早已发现,提示模型"逐步思考"可以提升其表现。但是通过端到端的试错方式来训练模型这样做,会使结果更加可靠,而且——正如我们在围棋或Dota等游戏中看到的那样——可以产生极其令人印象深刻的结果。
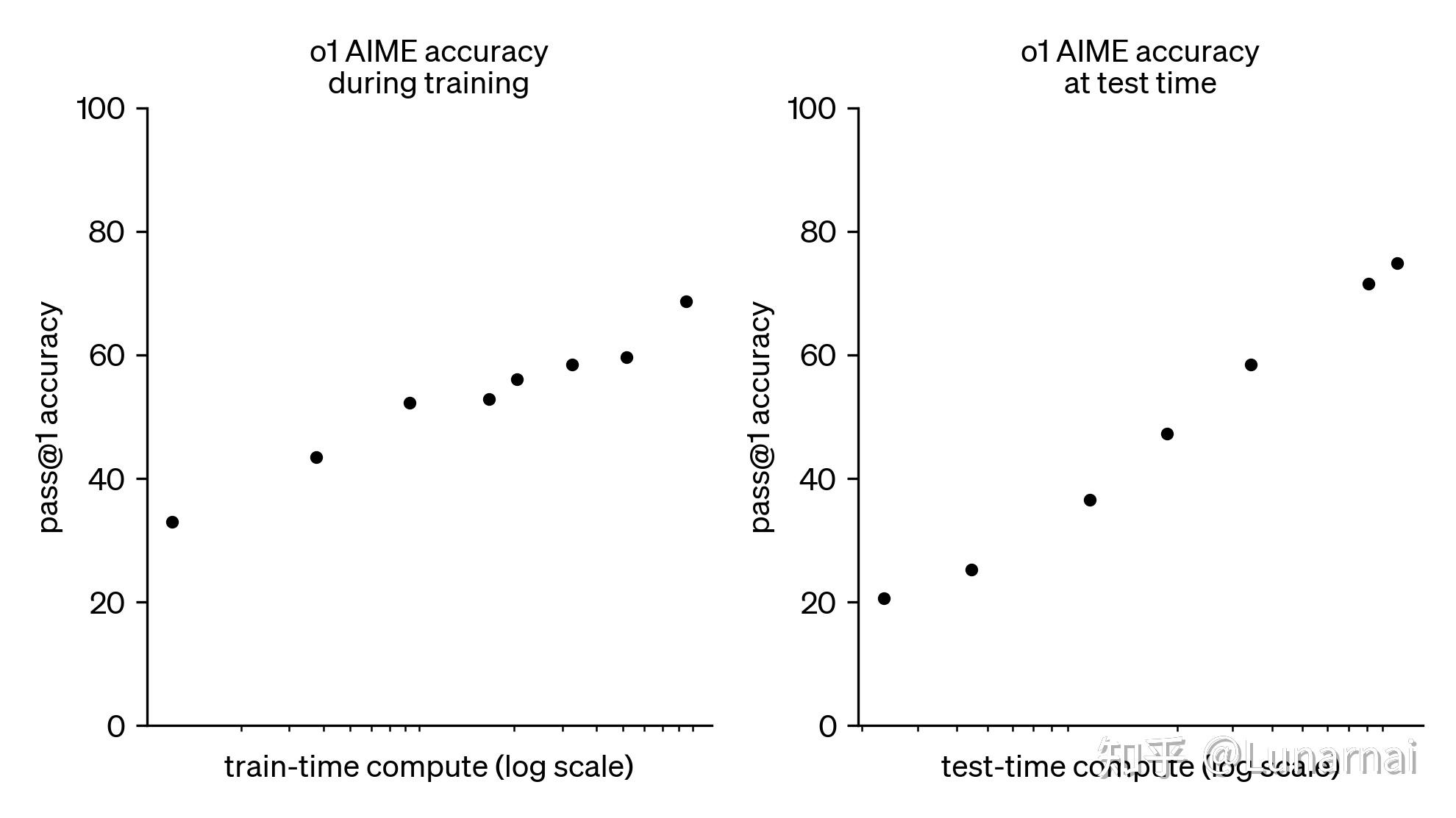
推理时间的 scale 对复杂问题的解决提升是有飞跃性的:
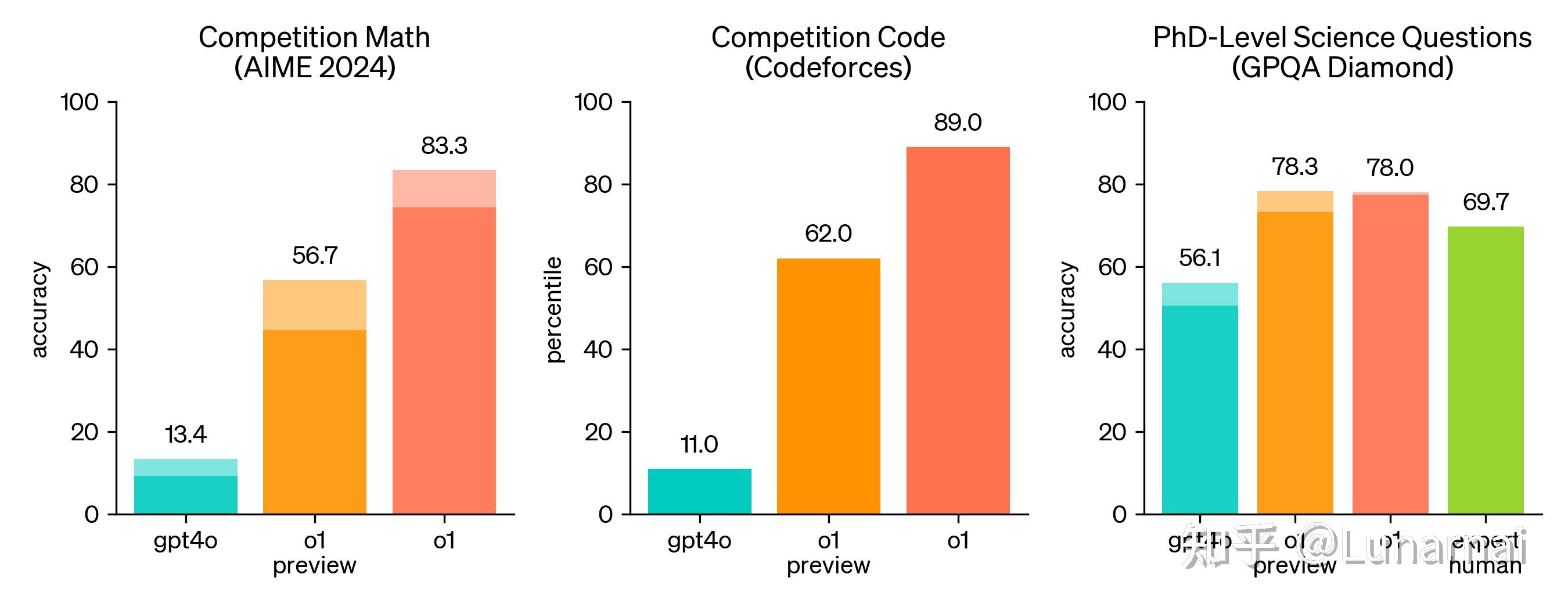
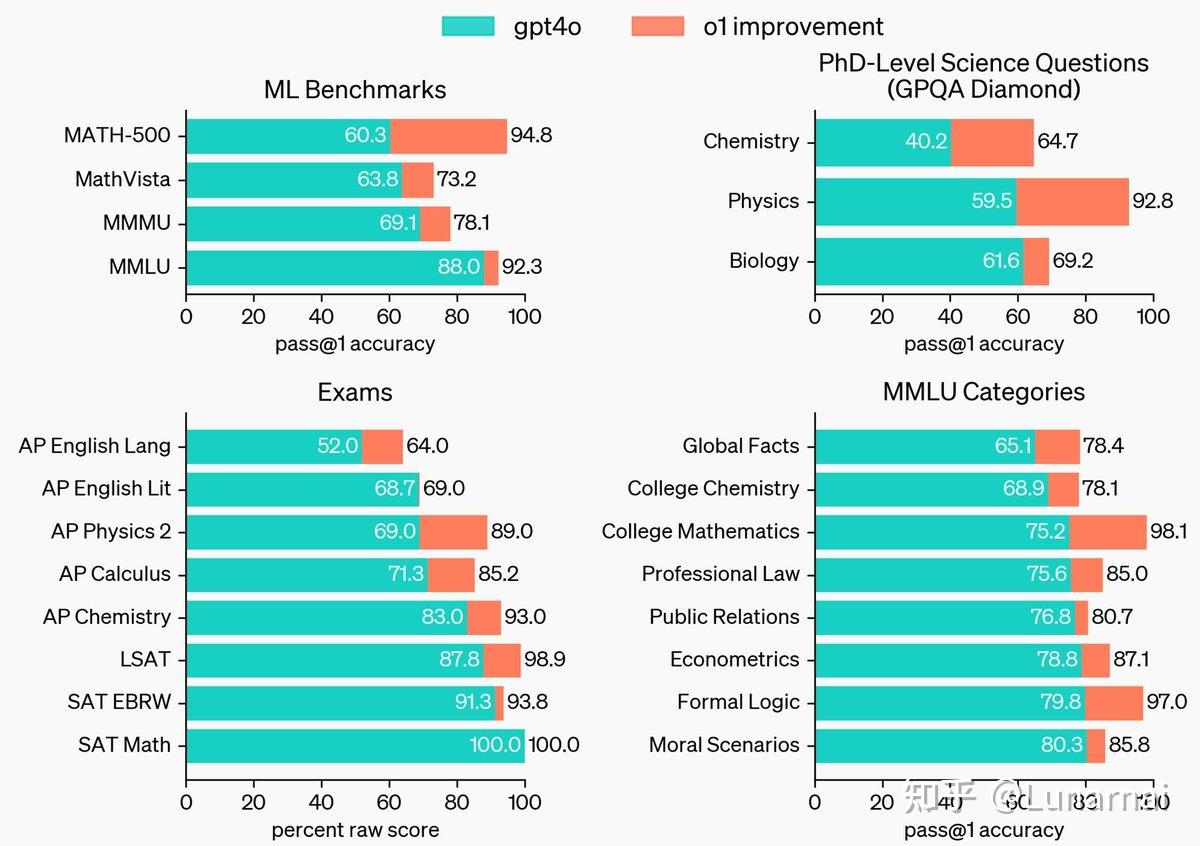
到这边,做 CoT 的同学狂喜(来活了,我就说这个方向有前途吧
其他同学不要着急,这个 end2end的CoT 是怎么做的呢,OpenAI 其实也提到了

于是做 RL 的同学狂喜(泪目,他们都说什么PPO/DPO 都不如洗数据,我大 RL 也有今天!
然后同时可以观察到,o1 的推理时间明显变长,有时甚至耗时十几秒。且 o1 相比 4o 的 context 也长了一倍,自然也能理解,毕竟引入大量反思的过程了。

于是,做 Long context 的同学狂喜(谁在说长上下文是屠龙技没啥实际用处我跟谁急
同时,做推理加速的同学也狂喜(夫人,你也不希望你的模型要几分钟才能告诉你答案吧
甚至,做agent的同学也狂喜(都说单步成功率是最大瓶颈,现在瓶颈无了,我的论文有了
事实上,在正式发布前,agent界的新星Devin就已经受邀内测了

做攻防的同学也狂喜,既然你说现在应对jailbreak已经很自如了(给叔叔看看你的大模型,你把cot藏哪啦?
Devin团队也提到了,o1其实对prompt的敏感度更高了,对prompt质量要求也更高了
> o1 requires denser context and is more sensitive to clutter and unnecessary tokens. Traditional prompting approaches often involve redundancy in giving instructions, which we found negatively impacted performance with o1.
O1 需要更密集的上下文,并且对杂乱内容和不必要的标记更加敏感。传统的提示方法通常在给出指令时存在冗余,我们发现这对 O1 的性能有负面影响。
于是,做prompt engineer的同学也狂喜(谁说模型越强我们越容易被淘汰
做Synthetic data的同学自然也是喜不自胜:挑选数理代码作为突破口,还不是因为这些领域的cot数据容易合成嘛
工程同学也狂喜,inference cost 的 scaling,必然也会引领一次工程上的适应和改造
投资同学狂喜(又能多烧一阵钱啦,前一阵闲的只能传传 AI 四小龙的八卦了
只能说 OpenAI 大善人啊,给这么多人赏饭吃。
当然,o1自然不是完美的
例如它的写作能力甚至还降了一点
例如,它还需要好几秒钟才能数对 strawberry 中有几个 r

例如,它比较 9.11和 9.8哪个大还要去拧巴得和重力那绕一圈(换个数字不一定会重复重力这一part。但是这个过程反应出来的问题是,1o缺乏对问题复杂度的良好评估,而且回答倾向于引入更多知识和步骤来解决问题。例如数r的时候能分十几个步骤出来
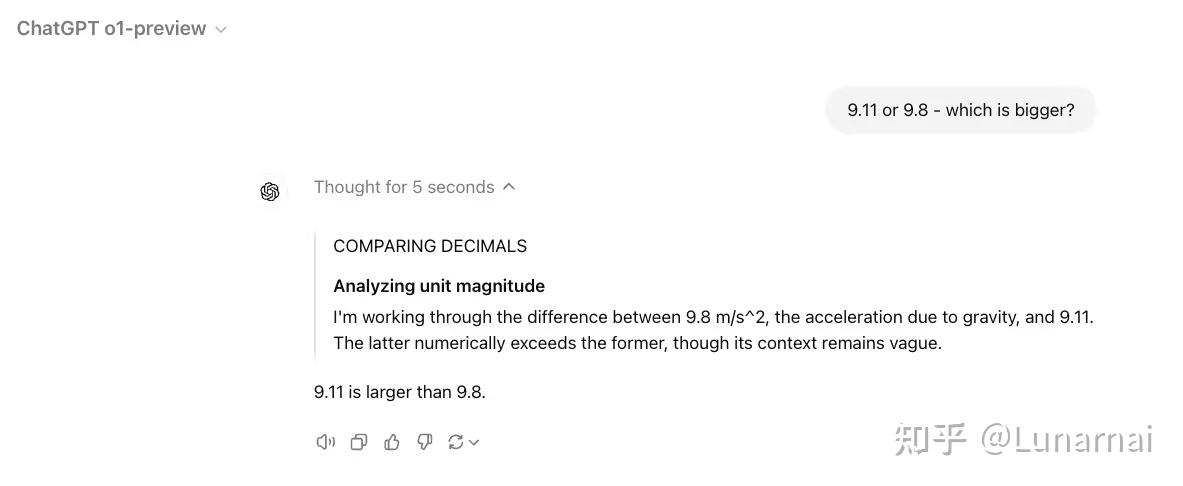
例如,openai还是一如既往的close(其实这次透露的信息算多的了我觉得
但是都不妨碍它掀开了一个新篇章的一角
也希望国内的老兄弟们能够尽快赶上,起来干活啦~
(太困了,随便写一点,明早再补充
 新公网安备 65010402001845号
新公网安备 65010402001845号