不会写复杂的SQL,该怎么学习?
我教你怎么写,用二个表就可以写出让你灵魂出窍头皮发麻的SQL。但是SQL写复杂不是目的,解决问题才是目的。
搞个业务需求,我杜撰一个吧。有客户表和客户订单表,我们要查出客户的信息并带上客户最后订单的订单重量。一个客户会有多个订单,只能出现最后一个订单的重量,其它的不要。
这需要二张表,客户表,客户订单表。我们看看以这二张表能写多复杂的查询。中间绝对不加任何表了。
先看表结构:表的主键我都用GUID,外键使用“GUID_表名”的规则。
IF NOT EXISTS(SELECT * FROM sys.objects
WHERE object_id = OBJECT_ID(N'[dbo].[Customer]') AND type in (N'U'))
CREATE TABLE Customer
(
GUID UNIQUEIDENTIFIER PRIMARY KEY DEFAULT NEWSEQUENTIALID(),
Name VARCHAR(100),
CID INT IDENTITY,
Email VARCHAR(200)
)
GO
IF NOT EXISTS(SELECT * FROM sys.objects
WHERE object_id = OBJECT_ID(N'[dbo].[CustomerOrder]') AND type in (N'U'))
CREATE TABLE CustomerOrder
(
GUID UNIQUEIDENTIFIER PRIMARY KEY DEFAULT NEWSEQUENTIALID(),
OID INT IDENTITY,
OrderDate DATETIME,
GoodsWeight DECIMAL(10, 2), --订单重量
GUID_Customer UNIQUEIDENTIFIER,
)
GO
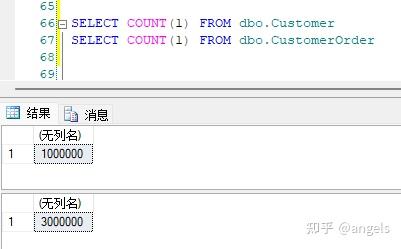
下面给表加入数据,我们就主表插入100万条数据吧,订单表插入300万条数据。
数据量大一些,可以把性能问题暴露出来。
DECLARE @Name INT = 0, @E VARCHAR(10) --C00000099
SELECT TOP 1 @Name=CAST(SUBSTRING(ISNULL(Name, 'C0000001'), 2, 8) AS INT) FROM dbo.Customer ORDER BY CID DESC
SELECT @Name
--客户表增加100万条记录
WHILE(@Name < 1000000)
BEGIN
SET @Name=@Name+1
SELECT @E = 'C' + RIGHT('0000000' + CAST(@Name AS VARCHAR(10)), 8)
INSERT dbo.Customer( Name, Email ) VALUES ( @E, @E+'@abc.com' )
END
--给订单表加300万条数据
INSERT dbo.CustomerOrder ( OrderDate, GoodsWeight, GUID_Customer )
SELECT GETDATE(), cast( floor(rand()*1000) as int), GUID FROM dbo.Customer
INSERT dbo.CustomerOrder ( OrderDate, GoodsWeight, GUID_Customer )
SELECT GETDATE(), cast( floor(rand()*1000) as int), GUID FROM dbo.Customer
INSERT dbo.CustomerOrder ( OrderDate, GoodsWeight, GUID_Customer )
SELECT GETDATE(), cast( floor(rand()*1000) as int), GUID FROM dbo.Customer
UPDATE dbo.CustomerOrder SET GoodsWeight=GoodsWeight - (OID % 100)
UPDATE dbo.CustomerOrder SET OrderDate=DATEADD(SECOND, OID, OrderDate)
GO
看看结果。
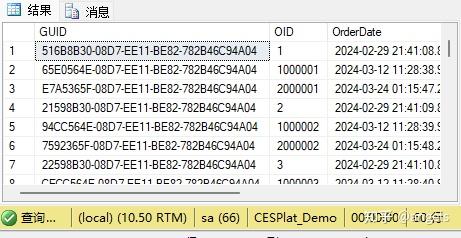
按这个要求,我们先把二个做连接,连接方案是Customer表取主键GUID字段,CustomerOrder表取外键GUID_Customer字段。
先写下面的SQL,看看效果
DECLARE @Page INT = 4, @PageCount INT = 20
SELECT TOP 20 C.Name, C.Email, CO.GoodsWeight FROM Customer C
JOIN dbo.CustomerOrder CO ON C.GUID=CO.GUID_Customer
ORDER BY C.Name
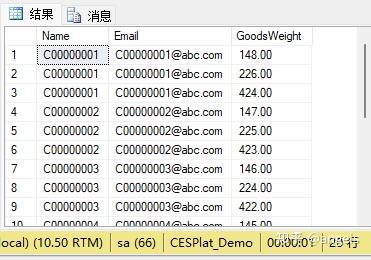
数据是20条没错,但是,数据明显不对,因为一个客户有多个订单,这个结果同个客户被多次显示了。
我们把订单表先处理一下,按业务要求把订单表先按客户分组,然后取出分组内最后的订单号,暂且认为单号最大的就是最后的。
如下
SELECT GUID_Customer, MAX(OID) OID FROM dbo.CustomerOrder GROUP BY GUID_Customer
我们把上面这条SQL和客户表做关联看一下。
这里要解锁一个技能,关系替换。本质上就是你可以把你查出来的数据那一整段SQL语句可以替换另一个SQL中的某个表或某个关系。
举个栗子。
--这个是第一个SQL语句A,可以查出Customer表CID小于100的数据
SELECT * FROM dbo.Customer WHERE CID < 100 --A
--这个是第二个SQL语句B,从Customer表查数据。
SELECT * FROM dbo.Customer --B
我下面做数据集替换。这里为了不花时间解释什么是关系,我暂时用数据集这个词代替关系这个词。
上面二个SQL中,第一个SQL执行的结果是一个数据集。而第二个SQL是从一个表中查数据。
这里,我们把第二的表是不是能看做数据集呢?如果是,那么SQL中的From关键字是不是可以从其它数据集中取数据呢?
答案是可以的,我们把第二个SQL改一下(上面的标记为B的),把Customer这个表用一个能查出数据集的SQL语句A代替。看结果。
SELECT * FROM (SELECT * FROM dbo.Customer WHERE CID < 100) C
/*
上面这条SQL,可以看到就是把B语句中的dbo.Customer用SELECT * FROM dbo.Customer WHERE CID < 100给换掉了。
要注意的是,替换后SQL是要有个名字的。这里我用C做数据集的名字。
这就是写复杂SQL的第一个技能,集合替换。为了可读性好一些,我写下面这样。每个查询独立占一行,有缩进。
*/
--上面的SQL后面都会用这种格式写,可读性会好一些。
SELECT * FROM
(
SELECT * FROM dbo.Customer WHERE CID < 100
) C --C是前面的括号里的查出来的数据的名字。这是必须的。
到这里,替换技能的说明就结束了。下面上我们要的结果。
SELECT TOP 20 C.Name, C.Email, CO.GUID_Customer, CO.OID FROM Customer C
JOIN
(
--先把CustomerOrder表的数据按GUID_Customer分组,然后取分组内最大的订单ID的值。
--这样就取到订单表中所有客户的最后一个订单的ID的集合。
SELECT GUID_Customer, MAX(OID) OID FROM dbo.CustomerOrder GROUP BY GUID_Customer
) CO ON C.GUID=CO.GUID_Customer --把数据集起名叫CO
ORDER BY C.Name

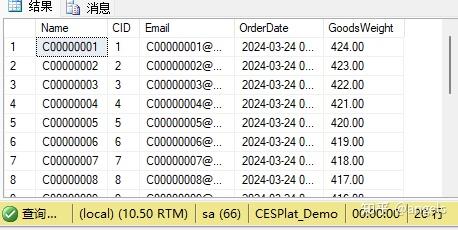
这次的结果客户不重复了,虽然我们没有取到订单的重量信息,但是在结果上看到,取到了订单表的唯一编号,因为有了这个订单号了,那接下来,再用订单号关联一下订单表。
SELECT TOP 20 C.Name, C.Email, CO.OID, O.OrderDate, O.GoodsWeight FROM Customer C
JOIN
(
SELECT GUID_Customer, MAX(OID) OID FROM dbo.CustomerOrder GROUP BY GUID_Customer
) CO ON C.GUID=CO.GUID_Customer
JOIN dbo.CustomerOrder O ON CO.OID=O.OID --用CO数据集里的订单ID和CustomerOrder表的订单做连接
ORDER BY C.Name
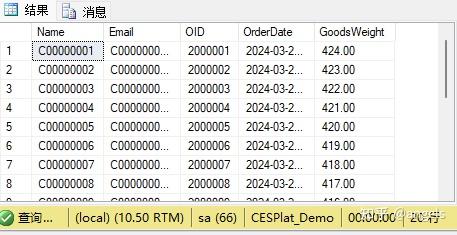
结果是出来了,但是有几个问题。
1,执行速度慢
2,不能分面,只是随机的取了20行。
3,如果客户没有订单,则这个客户就没有查出来。
我们先解决分页问题。使用开窗函数来做。
分页的方案:
先用开窗函数对客户表的CID字段排序并生成连续的编号,并形成一个数据集,
再从这个排序好的集中取指定页的数据。
利用前面解锁的关系替换技能,写出如下的SQL语句:
DECLARE @Page INT = 4, @PageCount INT = 20
SELECT * FROM
(
--将Customer表的数据,按CID排序好,并把编号放到RID列中。
SELECT ROW_NUMBER() OVER (ORDER BY CID) RID, * FROM dbo.Customer
) C --带有排好序的RID字段的数据集,起名为C
WHERE C.RID > (@Page - 1) * @PageCount AND C.RID <= @Page * @PageCount
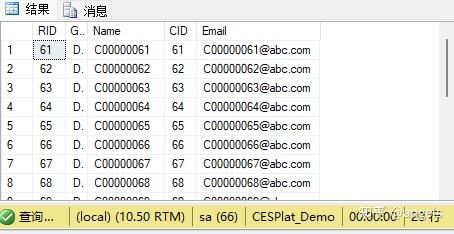
最后从C中取出指定页的数据,就是下面这行。不用解释了吧?找指定范围的RID。
C.RID > (@Page - 1) * @PageCount AND C.RID <= @Page * @PageCount
通过上面这段SQL我们能得到Customer表的完整数据,同时也是指定范围的数据。
接下来使用这个数据集,再和CustomerOrder关联,那就把分页问题解决了。
同时,连接我们就选择左连接,这样如果客户没有订单也会显示出来。
下面看完成的SQL
DECLARE @Page INT = 1, @PageCount INT = 20
SELECT CM.Name, CM.CID, CM.Email, O.OrderDate, O.GoodsWeight FROM
(
SELECT * FROM
(
--将Customer表的数据,按CID排序好,并把编号放到RID列中。
SELECT ROW_NUMBER() OVER (ORDER BY CID) RID, * FROM dbo.Customer
) C --带有排好序的RID字段的数据集,起名为C
WHERE C.RID > (@Page - 1) * @PageCount AND C.RID <= @Page * @PageCount
) CM --依然使用从一个数据集中查数据的方法。
LEFT JOIN
(
SELECT GUID_Customer, MAX(OID) OID FROM dbo.CustomerOrder GROUP BY GUID_Customer --A
) CO ON CM.GUID=CO.GUID_Customer
LEFT JOIN dbo.CustomerOrder O ON CO.OID=O.OID --用CO数据集里的订单ID和CustomerOrder表的订单做连接
ORDER BY CM.Name

上面这个SQL已经有点复杂了,但是性能没解决,我们继续。
我们先看上面SQL中的A语句,就是下面这句
SELECT GUID_Customer, MAX(OID) OID FROM dbo.CustomerOrder GROUP BY GUID_Customer --A
他是把CustomerOrder做一个分组,现在这个表里有300万条数据,以后可能还更多。
你说对300万数据进行分组和300条数据进行分组,哪个会更好一点,当然是300条的了。
那我们怎么把300万数据减少呢。我们这么看现在A这条语句的数据来源是CustomerOrder这个表。
前面我们解锁了一个关系替换的技能,已经用过一次了,现在再次来用。
怎么用呢,即然通过分页已经知道了准确的客户了,那么为什么不把CustomerOrder表这些客户相关的订单数据查出来,然后对查出来的数据做分组呢,说干就干。
在CustomerOrder表分离出当前分页的SQL如下。这里又解锁了一个技能,子查询。你可以用这个办法收缩数据库。
DECLARE @Page INT = 1, @PageCount INT = 20
SELECT * FROM dbo.CustomerOrder WHERE GUID_Customer IN
(
--查出当前分页上客户的主键GUID
SELECT C.GUID FROM
(
--将Customer表的数据,按CID排序好,并把编号放到RID列中。
SELECT ROW_NUMBER() OVER (ORDER BY CID) RID, * FROM dbo.Customer
) C --带有排好序的RID字段的数据集,起名为C
WHERE C.RID > (@Page - 1) * @PageCount AND C.RID <= @Page * @PageCount
)
上面这段SQL,完全可以替换CustomerOrder表来工作。这样,就把CustomerOrder收缩到很小很小了。
看下改进后的SQL
DECLARE @Page INT = 1, @PageCount INT = 20
SELECT CM.Name, CM.CID, CM.Email, O.OrderDate, O.GoodsWeight FROM
(
SELECT * FROM
(
--将Customer表的数据,按CID排序好,并把编号放到RID列中。
SELECT ROW_NUMBER() OVER (ORDER BY CID) RID, * FROM dbo.Customer
) C --带有排好序的RID字段的数据集,起名为C
WHERE C.RID > (@Page - 1) * @PageCount AND C.RID <= @Page * @PageCount
) CM --依然使用从一个数据集中查数据的方法。
LEFT JOIN
(
SELECT GUID_Customer, MAX(OID) OID FROM
(
SELECT * FROM dbo.CustomerOrder WHERE GUID_Customer IN
(
--查出当前分页上客户的主键GUID
SELECT C.GUID FROM
(
--将Customer表的数据,按CID排序好,并把编号放到RID列中。
SELECT ROW_NUMBER() OVER (ORDER BY CID) RID, * FROM dbo.Customer
) C --带有排好序的RID字段的数据集,起名为C
WHERE C.RID > (@Page - 1) * @PageCount AND C.RID <= @Page * @PageCount
)
) CustomerOrder GROUP BY GUID_Customer --A
) CO ON CM.GUID=CO.GUID_Customer
LEFT JOIN dbo.CustomerOrder O ON CO.OID=O.OID --用CO数据集里的订单ID和CustomerOrder表的订单做连接
ORDER BY CM.Name
这个还没完,可以看到最后的还有一个CustomerOrder,是不是也可以用这个方案缩小一下数据集呢。实际上不用了,但是为了把SQL搞复杂,还是做一下吧。
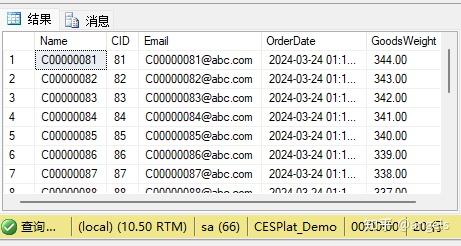
我们再来改进一下,同时页取第5页
DECLARE @Page INT = 5, @PageCount INT = 20
SELECT CM.Name, CM.CID, CM.Email, O.OrderDate, O.GoodsWeight FROM
(
SELECT * FROM
(
--将Customer表的数据,按CID排序好,并把编号放到RID列中。
SELECT ROW_NUMBER() OVER (ORDER BY CID) RID, * FROM dbo.Customer
) C --带有排好序的RID字段的数据集,起名为C
WHERE C.RID > (@Page - 1) * @PageCount AND C.RID <= @Page * @PageCount
) CM --依然使用从一个数据集中查数据的方法。
LEFT JOIN
(
SELECT GUID_Customer, MAX(OID) OID FROM
(
SELECT * FROM dbo.CustomerOrder WHERE GUID_Customer IN
(
--查出当前分页上客户的主键GUID
SELECT C.GUID FROM
(
--将Customer表的数据,按CID排序好,并把编号放到RID列中。
SELECT ROW_NUMBER() OVER (ORDER BY CID) RID, * FROM dbo.Customer
) C --带有排好序的RID字段的数据集,起名为C
WHERE C.RID > (@Page - 1) * @PageCount AND C.RID <= @Page * @PageCount
)
) CustomerOrder GROUP BY GUID_Customer --A
) CO ON CM.GUID=CO.GUID_Customer
LEFT JOIN
(
SELECT * FROM dbo.CustomerOrder WHERE GUID_Customer IN
(
--查出当前分页上客户的主键GUID
SELECT C.GUID FROM
(
--将Customer表的数据,按CID排序好,并把编号放到RID列中。
SELECT ROW_NUMBER() OVER (ORDER BY CID) RID, * FROM dbo.Customer
) C --带有排好序的RID字段的数据集,起名为C
WHERE C.RID > (@Page - 1) * @PageCount AND C.RID <= @Page * @PageCount
)
) O ON CO.OID=O.OID --用CO数据集里的订单ID和CustomerOrder表的订单做连接
ORDER BY CM.Name
但是这个SQL好吗?太复杂了,我们改进一下吧,使用临时表代替反复出现的查客户页的代码。
DECLARE @Page INT = 1, @PageCount INT = 20
SELECT *
INTO #MC
FROM
(
--将Customer表的数据,按CID排序好,并把编号放到RID列中。
SELECT ROW_NUMBER() OVER (ORDER BY CID) RID, * FROM dbo.Customer
) C --带有排好序的RID字段的数据集,起名为C
WHERE C.RID > (@Page - 1) * @PageCount AND C.RID <= @Page * @PageCount
SELECT CM.Name, CM.CID, CM.Email, O.OrderDate, O.GoodsWeight FROM #MC CM --依然使用从一个数据集中查数据的方法。
LEFT JOIN
(
SELECT GUID_Customer, MAX(OID) OID FROM
(
SELECT * FROM dbo.CustomerOrder WHERE GUID_Customer IN
(
SELECT GUID FROM #MC
)
) CustomerOrder GROUP BY GUID_Customer --A
) CO ON CM.GUID=CO.GUID_Customer
LEFT JOIN
(
SELECT * FROM dbo.CustomerOrder WHERE GUID_Customer IN
(
SELECT GUID FROM #MC
)
)
O ON CO.OID=O.OID --用CO数据集里的订单ID和CustomerOrder表的订单做连接
ORDER BY CM.Name
DROP TABLE #MC
SQL中使用二个表中一些字段做查询,为此我们创建索引。
EXEC dbo.base_CreateIndex @TableName = 'Customer'
@FileName = 'CID'
EXEC dbo.base_CreateIndex @TableName = 'CustomerOrder',
@FileName = 'GUID_Customer'
EXEC dbo.base_CreateIndex @TableName = 'CustomerOrder',
@FileName = 'OID'
--这个加索引的函数是我自己写的,你的电脑上肯定没有。
创建以上索引后,代码的执行时间就快了很多,清除缓存后,不加索引整个查询大约在4秒左右完成 。使用了索引后,清除缓存后,查询的执行时间在0秒完成了。
我们使用了一个关系替换的技能,就把一个二个表的查询可以写到如此复杂。当然写复杂的目的肯定不是为了复杂而复杂,一定是有原因的。
- 要加快查询的速度,简单的写法不一定快。表很小是可以的。
- 要提高查询的性能,减少内存占用。join前先缩小表。不然有时候可能会溢出的。
- 完成特定的功能。比如这个例子中的取多个订单中一条记录。
关注我吧,一个专注于SQL及软件设计的老程序员,我会每天分享工作中的点点滴滴。
 新公网安备 65010402001845号
新公网安备 65010402001845号