如何看待deepmind AlphaProof获得2024国际数学奥林匹克竞赛银牌?
占坑,慢慢答
如何理解它的强度
很强。它做出了 IMO 6 道题中的 4 道,获得了很靠前的排名(差点就金了)。
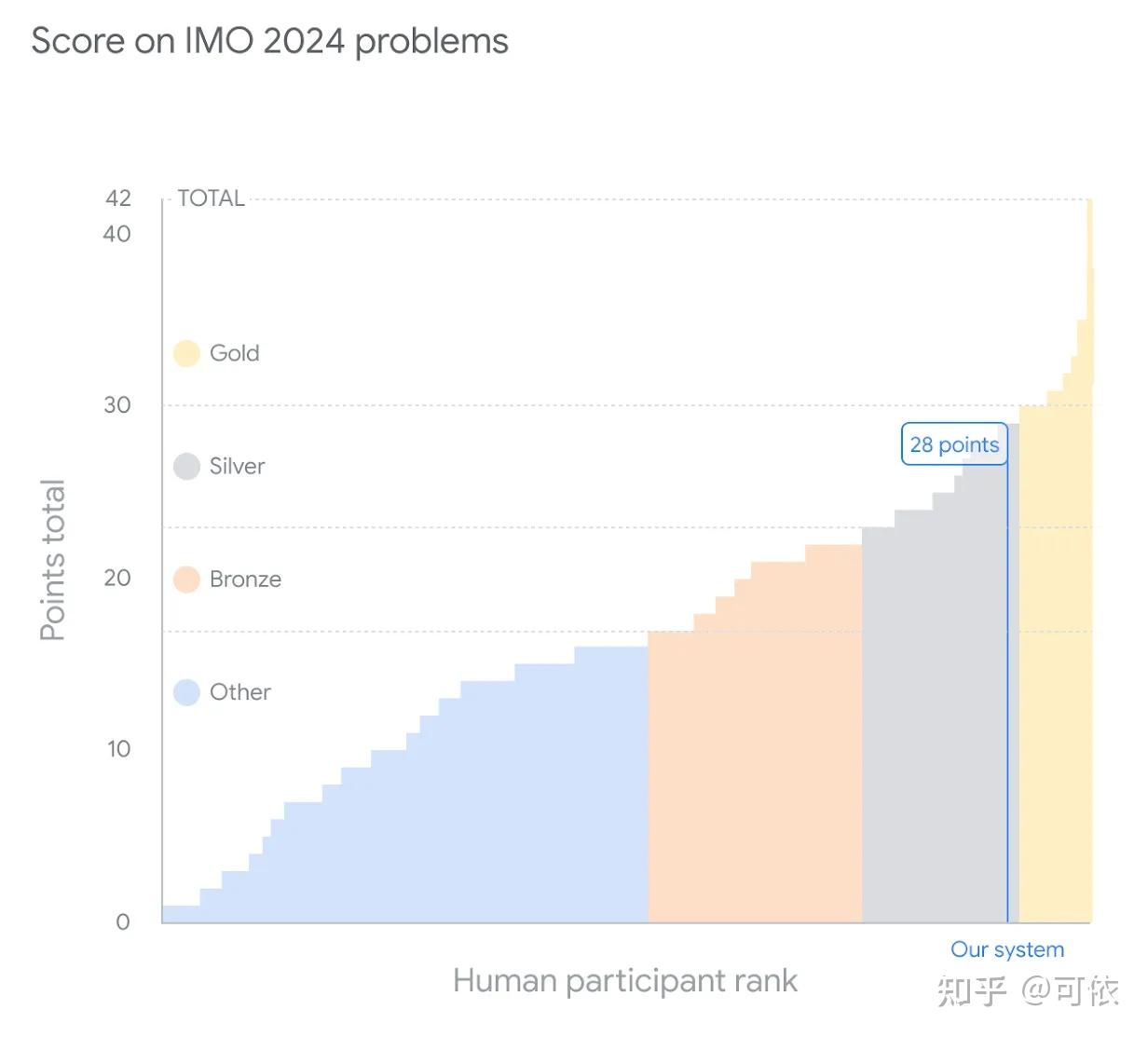
没有很多人想的那么强。根据 Timothy Gowers (菲尔兹奖得主,监督 deepmind 做题的数学家)解读,它做一道题需要几十个小时(而人总共不到十小时)。
它需要把用自然语言描述的数学题先由人形式化成一个定理,再交给 LLM 作为输入。
而且对于几何题和其他题,他用了两套不同的东西,这其实是非常不自然的,因为人不是组队参赛的。
它在证明过程中可以获得来自 proof assistant 的反馈,在完全生成证明之后可以明确地知道自己对不对。但人可能没有这些反馈,或者说人靠的是自己脑子的反馈。
AlphaProof
是用类似 AlphaZero 的办法训的(和自己下围棋),所以应该用了 MCTS。但是为什么到了这个年代才做出来呢?
一个难点在于如何获取反馈。围棋的反馈是很容易的,只要判断输赢就行了,但判断一个数学证明是否正确就难了,如果是自然语言描述的题目和题解是不好获得很精确的反馈的。
这也是为什么要用 lean 这种形式化证明的工具,这样子就可以获得来自 proof assistant 的精确的反馈。
另一个难点在于数据。AlphaZero 是这样的,围棋只要自己下下下就可以了,但是做数学题要考虑的就多了。大量的数学题数据是以自然语言形式存在的,而非形式语言。所以他们 finetune 了 gemini 来做自动形式化(autoformalization),把自然语言的问题转换为形式语言。
当然,这里的转换本身是有可能不对的,但是这不妨碍训练,因为一个错误的形式化其实是另一个不同的问题,如果能做出来有反馈,模型也是可以学的。
AlphaGeometry
AlphaGeometry 和 AlphaProof 还是挺不一样的,它的推理部分应该用了很多传统方法(其中包含了吴文俊提出的方法吴文俊,把几何问题转换成代数问题来自动解决)。
它的点在于合成数据(而非利用人类数据)和生成辅助线(这个传统方法不大会)。
它合成数据的时候先sample一堆前提,然后用传统方法在上面一通推理,可以得到一堆结论,对于每个结论都可以找到一个最小的前提集合可以恰好推出它,这样就造出来一道几何题。其中前提集合里和结论无关的就是辅助线,然后就可以拿来给llm学学学了。
这意味着什么,不意味着什么?
意味着llm可能可以辅助人类数学家。
假如人类数学家把自己需要的一些东西以合适的形式交给llm,可能可以从llm获得一些启发。
不意味着llm已经可以代替人类进行数学发现了。
因为 1)imo和数学研究比起来还是简单不少,很多复杂的命题连 formalization 都很难,搞不好人也写不出来。 2) 哪怕写出来了,也难说有足够的数据能学会。3)证明是一回事,提出新猜想是另一回事,自动提出猜想是另一个不同的数学机械化领域了。
当然在某些情况下还是有可能有些贡献的比如同样来自 deepmind 的 funsearch [4] 就通过搜索贪心的 priority 的办法发现了目前最大的 cap set。但是个人感觉这种推上下界的问题还是挺不一样的。
不意味着llm可以直接做到imo选手能做到的事情
alphaproof 是专门针对数学题找了一套很好的办法来做 RL,但是实际问题像下围棋和证明定理一样可以有这么好的反馈的还是太少,imo选手可能可以通过比较烂的反馈也学得很好,但是llm就难了。
参考资料
[1] https://x.com/wtgowers/status/1816509803407040909
[2] AI achieves silver-medal standard solving International Mathematical Olympiad problems
[3] https://www.nytimes.com/2024/07/25/science/ai-math-alphaproof-deepmind.html
[4] https://www.nature.com/articles/s41586-023-06924-6
 新公网安备 65010402001845号
新公网安备 65010402001845号