华为为什么要招聘数学博士?
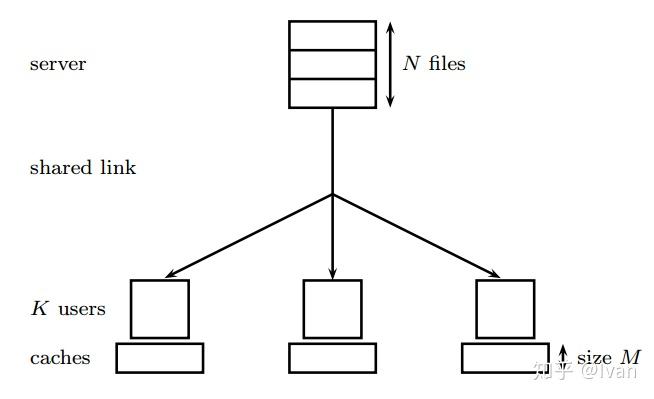
因为目前最热门的几个业界领域,有不少问题都卡在了数学上。我举一个缓存(Caching)的例子,无线网络的缓存问题大概是说,一个存储 个文件的服务器,文件大小设定为单位
,通过无噪声的广播信道与
个用户相关联。每个用户各自的缓存设备的容量为
。我们的缓存方案分为两个阶段:一是数据的放置阶段(Placement phase),在数据需求量较小的空闲时段,利用有余力的通信资源,向每个用户的缓存设备中放置大小为
的数据;二是数据的分发阶段(Delivery phase),假定在数据需求高峰期,每个用户随机向服务器请求一个完整的文件,服务器综合考虑这些需求,通过广播的形式传输大小为R的数据,以满足所有用户的需要。这个思路有点像天荒坪发电站搞峰谷电的感觉。
最平凡的思路是,各用户分别缓存每个文件的 比例的数据,在数据分发阶段服务器再将各用户所缺失的各自
部分的数据逐个发放,此时
。为提高传输效率,2014年,贝尔实验室的Ali和Niesen利用网络编码的思想,创造性地提出了编码缓存方案。在放置阶段,各用户的缓存按一定编码规律存储,获得局部缓存增益;在分发阶段,利用已有的缓存信息之间的关系,设计所需广播内容的一定的编码组合,使得多个用户可以同时从单次的信息中译码得到所需的部分信息,从而得到全局缓存增益,但是其局限在于,要将每个文件等分为一个随着用户数量K而呈指数增长的参数,众所周知,指数级别的分划,在算法上的难以实现的。而后西南交通大学的一组研究人员用 Array的语言刻画了组合缓存问题,并构造了另一种方案,虽然
相比较而言稍有牺牲,但相对Ali-Niesen方案而言大幅减少了
的数目,但遗憾的是,
依然是随着
而呈指数增长的。此后,此问题继续转化为3-partite,3-graph上的一个Turán型问题(所需禁止的是“六个顶点诱导得到三条边”这样一个子图结构,这其实是极值图论中著名的(6,3)-问题),提出的缓存方案依然保持常数级别的
,但
减小到了
的次指数级别。接着利用类似的思路,Shanmugam等人通过极值图论中的重要研究对象Ruzsa-Szemeredi图得到的缓存方案中,
达到
的线性级别,而
为
的多项式级别。
那么,这一方向的终极目标则是:我们希望得到 为
的多项式级别,且
为常数级别时的缓存方案。或者能证明这种方案的存在性(不存在性)。
显然到了现在,关于文件划分数能否转化成多项式级别,即达到工业可用的级别,完全取决于数学上能否构造出满足某些Properties的Hypergraph的问题了。
以上例子大概能够说明为什么华为这样的公司需要招数学博士。
我觉得加入像华为的数学研究所这样的地方,更大的好处是你可以真正了解若干年内的业界,真正关心的问题是什么。
不过话又说回来,还是应该多学点数学,只有具备解决一些困难数学问题的能力,再进入像华为办的那些研究所,才有希望真正解决业界关心的问题。
 新公网安备 65010402001845号
新公网安备 65010402001845号