本科是遥感的人,现在都怎么样了呢?
2024年3月30日更新:
如果要迅速发论文以方便找工作的话,现在遥感里面当之无愧的论文热点就是Mamba+遥感,或者说Mamba的热潮已经从大语言模型来到了视觉领域,并迅速涌现了一大批使用Mamba进行视觉任务的研究。
Mamba+遥感的首个工作可以参照下面的文章,它首次将SSM引入到遥感的密集预测任务中,提出了RS-Mamba来处理大遥感图像,并针对遥感场景对模型进行了设计。
walking shadow:Mamba入局遥感!RS-Mamba:首次使用SSM进行大遥感图像的语义分割与变化检测要了解SSM和Mamba是什么,可以从下面两个回答中进行学习:
如何理解 Mamba 模型 Selective State Spaces?
如何理解语言模型的训练和推理复杂度?
走遥感+计算机视觉方向,现在已经在大厂里面找到了实习,正在进行遥感大模型方向的研究,熬过现在大模型的研发阶段,等到毕业的时候乐观估计应该能赶上大模型的落地赚钱阶段,到时候应该能加入到大模型的热潮中。
个人经验来看,遥感+计算机视觉的发展前景可以很不错,关键还得看个人。因为遥感在数据格式和任务方面是和计算机视觉强关联的,计算机视觉之前很火热,现在乘上了大模型的东风,连带着遥感领域也一起吹起来了。如果题主关注遥感领域大模型的发展,就可以发现不仅仅是通用视觉领域和大语言模型领域有各种大模型的“百模大战”,遥感领域的大模型也是此起彼伏,半年的时间就有很多大模型发布。
所以如果是要直接就业,机会主要集中在遥感+计算机视觉方面。只从算法岗和科研岗来说,不管是通用视觉领域,还是计算机视觉与遥感交叉领域,大厂都有对应的岗位。如果是要做科研,那各种科研院所的名额和岗位都是满满的,随着大模型发展也会进一步火热。而这两种美好前景的前提都是你得有对应的成果,直白一点来说就是论文。
通用视觉领域的岗位方面,由于遥感图像和自然图像、雷达数据和点云在数据格式上是契合的,很多通用视觉领域的任务在遥感领域也都是有对应的任务的,比如语义分割、目标检测等,因此这些岗位也会看你的遥感+深度学习方面的成果,毕竟方法和技术还是很相同的。
计算机视觉和遥感交叉领域,在阿里达摩院、上海人工智能实验室等多个大厂都有岗位,岗位会更少一些,不过竞争的压力也会小很多。
所以关键就是多发论文,论文发的多,遥感领域的论文也是可以得到大厂认可的。而发论文的方向,从我的研究领域来看,一个很有潜力并且好发论文的方向就是特殊场景的变化检测。
现在的大模型时代,各个遥感任务的普通场景被卷烂了,而语义分割和目标检测这种任务其实可以算是从计算机视觉领域迁移过来的,在遥感场景中基本都是普通场景。但是变化检测是遥感领域的特定任务,虽然普通场景也被遥感大模型卷烂了,但在特殊场景还是一篇蓝海,可以在特殊场景里面多发几篇论文,之后就业基本没问题。从长远的一段时间来看,大模型对于特殊的复杂场景是鞭长莫及的,而特殊场景有自身的科学问题可以解决,这使得我们在特殊场景上的工作是有其科学意义的,在发论文方面也更有潜力。
目前特殊场景的变化检测的研究还很少,正是发论文的蓝海。要在变化检测的特殊场景下开展工作,可以使用下面研究的架构作为基础,这个架构针对变化检测的特殊场景进行了设计,解决了特殊场景里面的问题。论文和代码都是开源的,上手难度低,在这个架构的基础上,可以迅速在变化检测中的特殊场景开展工作。
写在前面
打开变化检测的论文一看,就是xx团队构建了一个xx模型,用了xx模块和xx trick,在xx数据集上把xx指标刷的更高。想必很多做变化检测任务的人都对此深有体会,因为变化检测任务看起来就和语义分割任务一样,除了刷点以外没有什么其他可以做的。
然而大模型的横空出世,使得改改模型刷刷点的模型变得更加困难了,因为大模型在有充足数据量的情况下,表现总是能更好的,大模型已然成了刷点的未来方向。但是大模型一来代码门槛高,二来也非常消耗资源,小团队冲大模型也很难冲得过大团队,盲目的选择大模型并不是一个很好的选择。
因此我们的工作不能够局限于刷点,但是又可以往什么方向拓展呢?一个很好的选择是场景。因为遥感领域中天然就有很多复杂的场景,而现在大模型主要能够做的仍然是建筑物的变化检测,在其他场景中总是很难有充足的数据,因此选择一个或者若干个特定的变化检测场景对我们的工作是很有利的。在特定的场景中我们可以针对场景的特点,设计出一些特殊的模块来提升模型的表现,这样相较于其他提点工作所说的贡献(比如引入多尺度、注意力等做烂了的东西),我们的贡献实质上是解决了特定场景中的科学问题,我们的工作是有现实意义的,从而论文也更容易发表。
那该针对什么变化检测场景呢?我推荐的是类内变化检测场景和多视角变化检测场景,如下图所示。类内变化检测场景是指不同时相的遥感图像之间有多种地物发生了变化,但是变化标签只告诉你哪些地方变化的,而不指示变化的类别是什么,比如图中发生变化的地物包括道路、建筑物、裸地,但是变化标签并不包含变化类别信息。多视角变化检测场景是指由于卫星的拍摄角度会发生变化,在不同时间获得的遥感图像的成像角度也不同,比如图中的时相1图像拍到了建筑物的侧面,但是时相2图像只拍到了建筑物的顶面。

这两个场景属于变化检测中研究的新兴场景,复杂的场景使得模型的效果往往不佳,因此构建模型并提高它们在这些场景中的表现大有可为。同时这两个场景也都有对应的公开数据集(SYSU和NJDS),基本直接上手构建模型即可,省时省力轻松出成果。
要介绍的这篇文章正是根据这两个场景的特点,提出了一种全新的变化检测基础架构,解决了之前的变化检测架构在这些场景中存在的不足。而基于这一基础架构,有大量的工作可以在上面开展,不管是直接组合各种已有的模块,还是设计自己的模块再组合上去,都是值得一做的工作。论文的代码也已经开源,上手即可使用。
概述
这项研究的核心贡献就是,提出了一种全新的变化检测基础框架,解决了之前的两种基础框架存在的结构性问题,在变化检测的多个场景下都能够取得最好的效果,能够成为后续变化检测研究的基础。
论文由南京大学高分辨率遥感实验室,于2023年10月26日发表于遥感顶刊《IEEE Transactions on Geoscience and Remote Sensing》,赵思杰为第一作者。
论文:Exchanging Dual Encoder-Decoder: A New Strategy for Change Detection with Semantic Guidance and Spatial Localization
代码:
https://github.com/walking-shadow/Semantic-guidance-and-spatial-localization-networkgithub.com/walking-shadow/Semantic-guidance-and-spatial-localization-network研究背景
近年来大量深度学习方法被应用到遥感图像变化检测任务中,这些方法主要基于多编码器-单解码器(Multiple encoders and single decoder, MESD)和双编码器-解码器(Dual encoder-decoder, DED)这两种基础架构,它们在单一场景下能够取得优良的效果,但是在多场景的通用性表现仍然存在不足。
网络结构上,如图1a所示,MESD由多个具有共享权重的编码器和一个单解码器组成。两时相遥感图像通过多编码器提取两时相特征,随后多时相特征在单编码器中融合,检测发生变化的地物。
核心思想上,如图2a所示,MESD利用两时相遥感图像的语义融合特征进行变化检测,由于两时相特征进行的是特征级融合,一个时相中变化地物的特征会被另一个时相中在同一空间位置的背景特征所干扰,从而导致模型难以准确地确定变化地物。
网络结构上,如图1b所示,DED由两个共享权重的编码器-解码器和一个单解码器组成,遥感图像通过双编码器-解码器分割出目标地物特征,并在单解码器中进行决策级融合,从而解决了两时相特征相互干扰的问题。
核心思想上,如图2b所示,DED先分割出两时相遥感图像的目标地物,然后对比两时相目标地物特征得到变化检测结果,它通过对两时相特征进行决策级融合,从而解决了MESD中的问题。然而,在只有变化标签而没有变化类型标签的类内变化检测场景中,DED难以分割出两时相遥感图像中的目标地物。在具有视角差异的多视角建筑物变化检测场景中,DED也无法区分变化地物和未变化地物由于不同视角导致的伪变化。

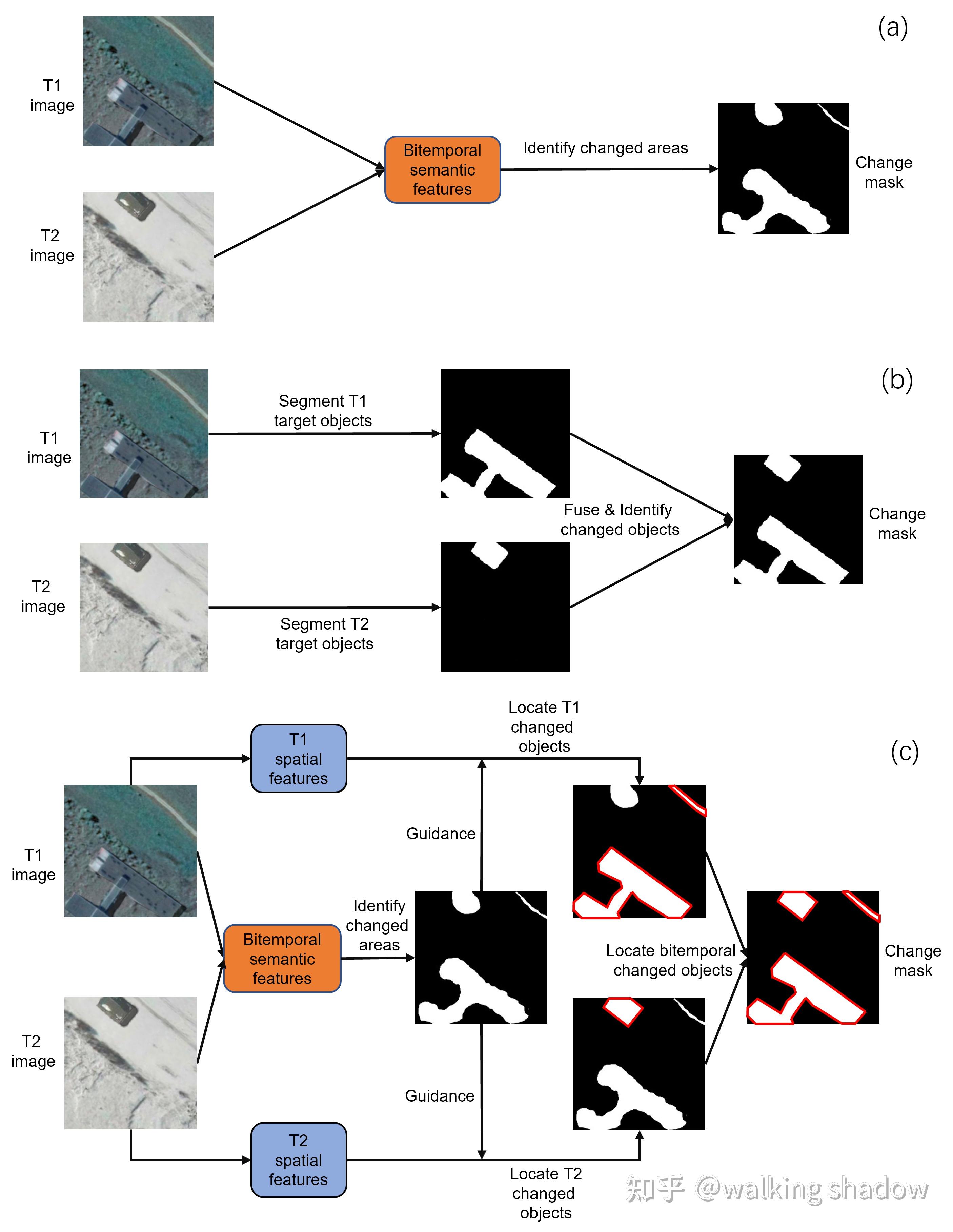
针对上述问题,我们提出了一种语义引导与空间定位的变化检测新思路,解决了既有基础架构存在的不足,实现了在多个变化检测场景(类内变化检测、单视角建筑物变化检测、多视角建筑物变化检测)中优越的表现,为变化检测任务提供了通用的深度学习架构。
这一变化检测思路利用语义引导与空间定位实现多场景通用的变化检测,根据这一思路,我们构建了一个交换式双编码器-解码器(Exchanging dual encoder-decoder)基础架构(简单结构参考图1c,复杂结构参考图3)。
在网络结构上,简单结构如图1c所示,与DED类似,EDED由两个具有共享权重的编码器-解码器和一个单解码器组成。不同的是,复杂结构如图3所示,两时相图像在双编码器中提取两时相特征后,模型在通道维度上对半交换两时相编码器特征,使得两时相特征都具有两时相图像的丰富的语义特征。因此编码器能够利用两时相语义特征来确定大致的变化区域,以此作为后续精确定位变化地物的引导。随后,两时相特征通过跳跃连接与两时相编码器特征融合,通过每个时相的编码器特征中的丰富空间特征来精确定位对应时相中的变化地物。最后,由于每个时相的解码器特征都精确定位了该时相中的变化地物,模型将两时相解码器特征在单解码器中融合,从而准确地定位所有变化地物。
在核心思想上,如图2c所示,两时相遥感图像通过两个分支的编码器,首先利用两时相遥感影像共同的语义特征确定出大致的变化区域,为后续变化地物的精确定位提供引导,然后使用每个时相遥感影像自身的空间特征精确定位自身时相中的变化地物,最后融合两时相变化地物特征,准确地定位出所有变化地物。
EDED对两时相变化地物特征进行决策级融合,从而解决了MESD中两时相特征相互干扰的问题。相较于DED而言,在类内变化检测场景中,EDED能够利用变化特征而非单时相特征来确定两时相遥感图像的变化地物而非目标地物,从而能够很好的判断出变化地物;在多视角建筑物变化检测场景中,EDED可以通过两时相遥感图像的语义特征来区分真实变化和视角差异导致的伪变化,因此可以准备的判别出真实变化地物。因此,EDED解决了既有架构中存在的不足,能够应用于多个变化检测场景。

根据这一基础架构,如图4所示,我们构建了一个语义引导与空间定位网络(Semantic guidance and spatial localization network, SGSLN)变化检测模型。

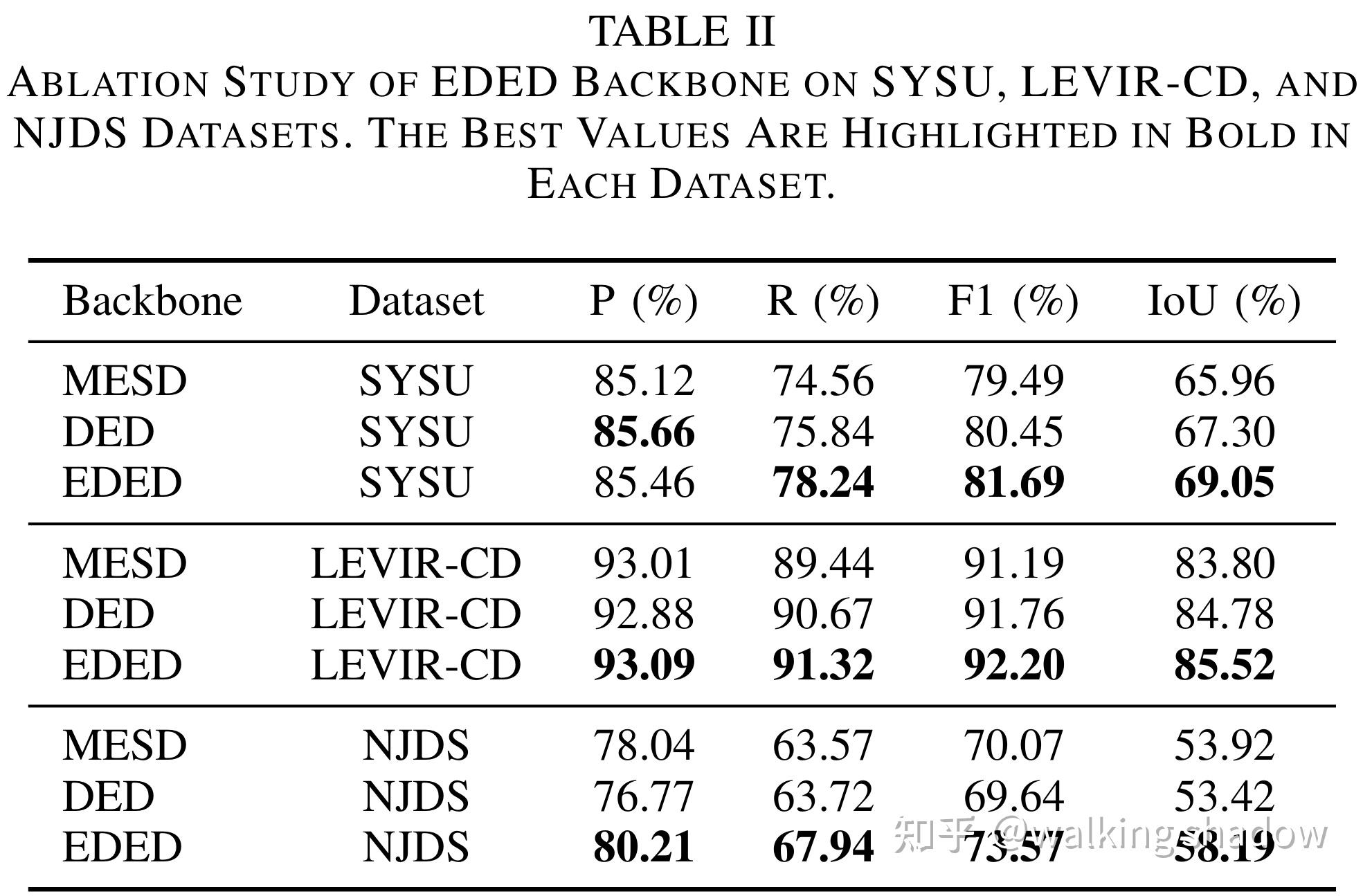
我们在类内变化检测数据集(CDD和SYSU)、单视角建筑物变化检测数据集(WHU、LEVIR CD和LEVIR-CD+)、多视角建筑物变化检测数据集(NJDS)上进行了广泛的实验。如图5所示,结果表明,EDED在多个场景中优于MESD和DED。在F1-Score指标上,EDED在类内变化检测场景(SYSU)、单视角建筑物变化检测场景(LEVIR-CD)和多视角建筑物变化检测场景(NJDS)中的提升分别达到了1.24%、0.44%和3.5%。
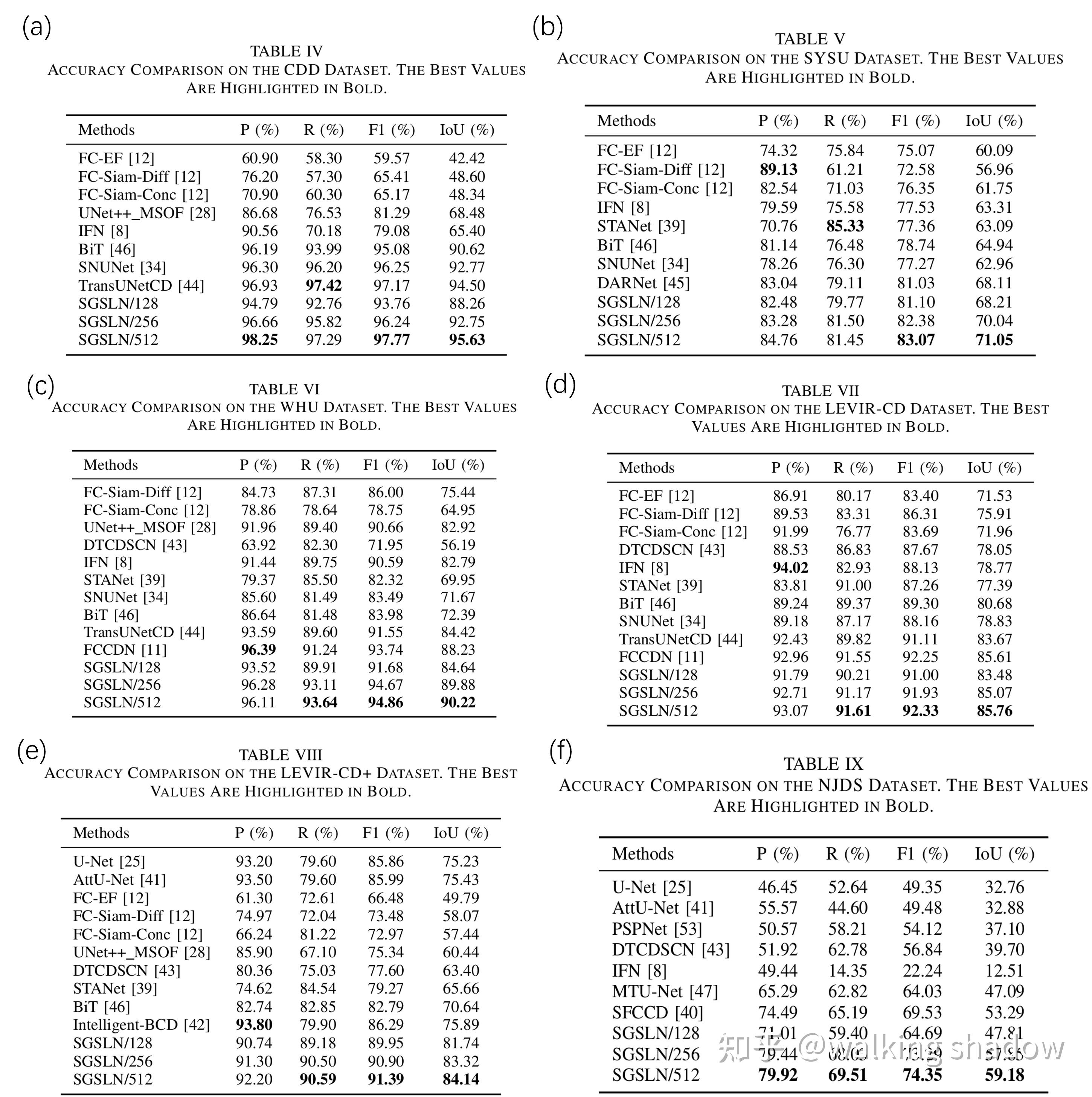
通过SGSLN与其他变化检测方法在多个场景下的对比实验,我们发现SGSLN在多个场景中的表现均有很大的提升(图5)。如图6所示,在类内变化检测场景(CDD和SYSU)中,模型的F1-Score分别提升了0.60%和2.04%(图6a-b);在单视角建筑物变化检测场景(WHU、LEVIR-CD和LEVIR-CD+)中,模型的F1-Score分别提升了1.12%、0.08%和5.10%(图6c-e);在多视角建筑物变化检测场景(NJDS)中,模型的F1-Score提升了4.82%(图6f)。
EDED解决了既有架构MESD和DED存在的问题,是深度学习变化检测中极具潜力的新架构。基于EDED构建的SGSLN在多个场景中取得了优异的表现,但仍只挖掘了这一架构的部分潜力。期望未来的研究能在EDED的基础上实现性能更好、通用性更强的多场景通用变化检测模型。
后记
该研究开源的代码同样适合作为变化检测的框架使用,上手即用,修改模型即可,具体可以参考文章
遥感变化检测代码框架极简实现代码框架好用的话,欢迎留下一个star。对于本文有任何疑问,也可以评论或者私信询问,欢迎多多使用这一通用变化检测架构和多多引用论文。
 新公网安备 65010402001845号
新公网安备 65010402001845号