AI领域的agent是什么意思?
这将改变你对人工智能及其功能的看法
https://zoumanakeita.medium.com/?source=post_page-----fb26789b1560--------------------------------动机
正如一句非洲谚语所说:
独自一人,我们走得更快。团结一心,我们走得更远。
这也与没有人能成为所有领域的专家这一理念有关。团队合作和有效委派任务对于实现伟大目标至关重要。AI Agents类似的原则也适用于大型语言模型 (LLM)。我们可以组合多个 LLM 或,每个 LLM 专注于特定领域,而不是让单个 LLM 处理复杂任务。
这一策略可以带来更强大的系统和更高质量的结果。
在本文中你将了解:
- 什么
AI Agents是 - 为什么值得考虑使用它们来解决实际用例
- 如何
AI Agents从头开始创建一个完整的系统
系统总体工作流程
在深入研究任何编码之前,让我们先清楚地了解本文中构建的系统的主要组件。
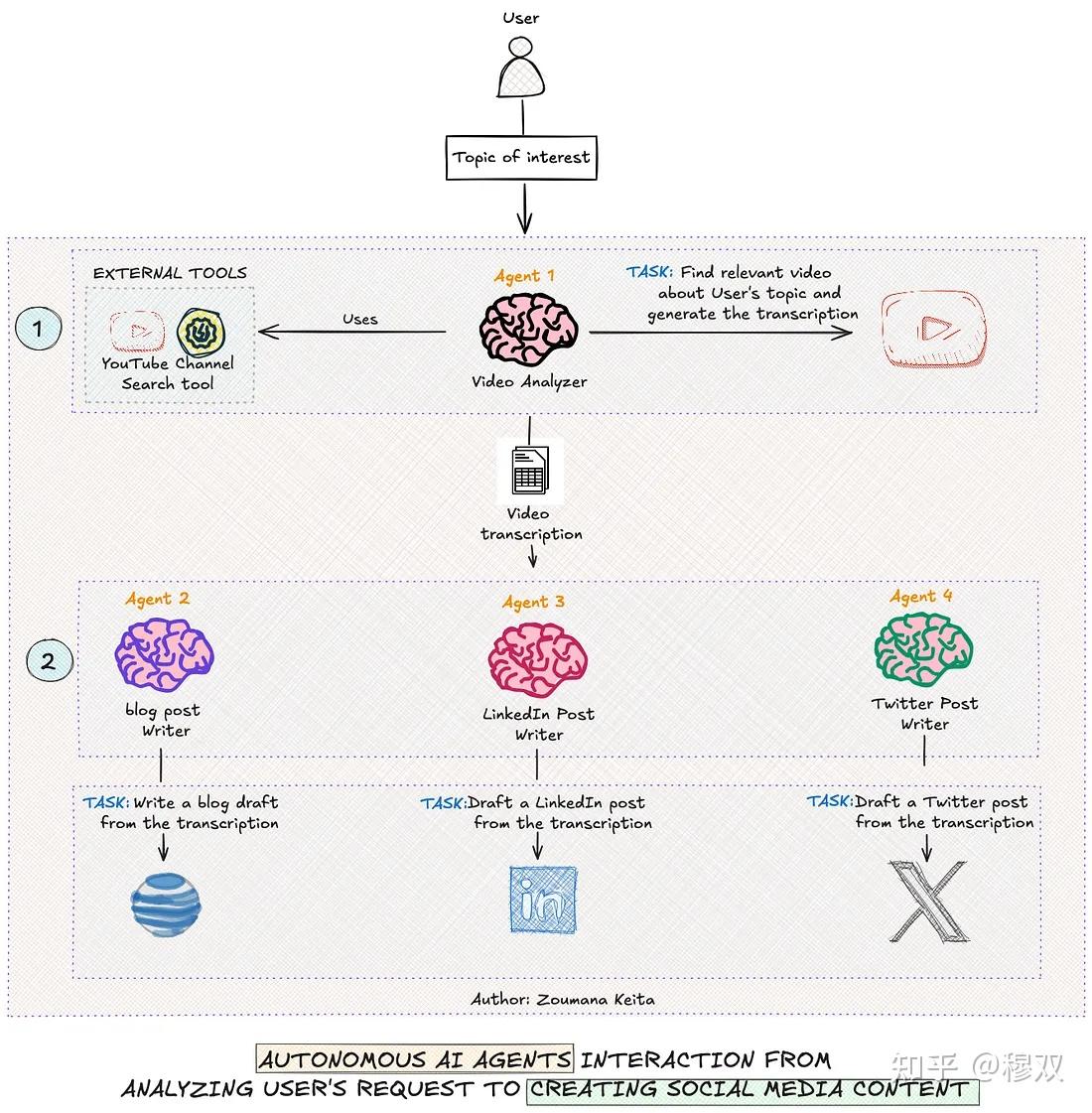
- 该工作流程总共有四个代理,每个代理都有一套专门的技能。
- 首先,用户的请求提交给系统。
Agent 1或者Video Analyzer使用外部工具(例如)在互联网上进行深入研究,以查找与用户请求相关的信息YouTube Channel Search。该代理的结果将发送到下一个代理进行进一步处理。Agent 2或者blog post writer利用以前的结果来撰写一篇全面的博客文章。- 与 类似
Agent 2,Agent 3和Agent 4也分别创建引人入胜的 LinkedIn 帖子和推文。 Agent 2、Agent 3和的响应Agent 4都保存到不同的 markdown 文件中,可供最终用户使用。
为什么我们应该关心人工智能代理,而不是单一的 LLM?
如果您还记得我写的关于使用 LLM 进行文档解析的文章,您会注意到这个请求的任务是单片的,这意味着 LLM 的任务只有一个目标:Data Extraction。
这种方法的局限性在处理更复杂、多步骤的任务时显而易见。其中一些局限性如下所示:
1.任务执行的灵活性
Single prompted LLMs需要为每个任务仔细编写提示,并且当期望与初始任务要求发生变化时可能难以更新。AI Agents将这些复杂性分解为子任务,调整其行为,而不需要在快速工程中付出大量努力。
2. 任务连续性和情境保留
Single prompted LLMs可能会丢失之前互动中的重要背景信息。这是因为它们主要在单个对话轮次的限制下运行。AI Agents提供了在不同的交互中维护上下文的能力,并且每个代理可以参考前一个代理的响应来完成他们预期执行的操作。
3. 专业化与互动
Single prompted LLMs可能经过广泛的微调后拥有专业的领域专业知识,这可能会耗费时间和金钱。AI Agents另一方面,可以设计为一组专门的模型,其中每个模型专注于一个特定的任务,例如researcher,,blog writer。social media expert
4. 互联网接入
Single prompted LLMs依赖于预定义的知识库,该知识库可能不是最新的,从而导致幻觉或访问受限。AI Agents能够访问互联网,使他们能够提供更多最新信息,从而做出更好的决策。
构建内容创建工作流程
在本节中,我们将探讨如何agentic workflow在对用户主题进行广泛研究之后,利用创建一个撰写博客帖子、LinkedIn 内容和 Twitter 帖子的系统。
代码结构如下::
project
|
|---Multi_Agents_For_Content_Creation.ipynb
|
data
|
|---- blog-post.md
|---- linkedin-post.md
|---- tweet.md
project文件夹是根文件夹,包含data文件夹和笔记本data文件夹目前为空,但在执行整体工作流程后应包含以下三个 markdown 文件:blog-post.md、linkedin-post.md和tweet.md- 每个 markdown 文件包含相应代理执行任务的结果
Agents Creation With Their Roles and Tasks创建代理及其角色和任务
现在我们已经在前面的部分探讨了每个代理的角色,让我们看看如何实际创建它们,以及它们的角色和任务。
在此之前,让我们先建立先决条件,以便我们更好地履行这些角色和任务。
Now that we have explored what each agent’s role is in the previous sections, let’s see how to actually create them, along with their roles and tasks.
Before that, let set up the prerequisites for us to better implement those roles and tasks.
先决条件
该代码是从 Google Colab 笔记本运行的,我们的用例只需要两个库:openai和crewai[tools],它们可以按如下方式安装。
%%bash
pip -qqq install 'crewai[tools]'
pip -qqq install youtube-transcript-api
pip -qqq install yt_dlp
成功安装库后,下一步是导入以下必要的模块:
import os
from crewai import Agent
from google.colab import userdata
from crewai import Crew, Process
from crewai_tools import YoutubeChannelSearchTool
from crewai import Task
每个代理都利用 OpenAI模型,我们需要通过以下方式 OPENAI API KEY设置对gpt-4o模型的访问:
OPENAI_API_KEY = userdata.get('OPEN_AI_KEY')
model_ID = userdata.get('GPT_MODEL')
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
os.environ["OPENAI_MODEL_NAME"] = model_ID
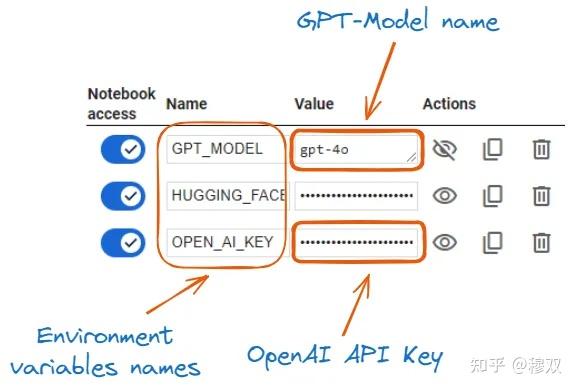
- First we access both the
OPEN_AI_KEYandGPT_MODELfrom Google colab secrets using the built-inuserdata.getfunction. - Then we set up both the
OPEN AI KEYandgpt-4omodel using theos.environfunction. - 完成以上两个步骤后,使用该模型创建代理应该不会有任何问题。.
代理人及其角色Agents and their Roles
通过该类Agent,我们可以通过主要提供以下属性来创建一个代理:role、goal、backstory和memory。
只有Agent 1或Video Analyzer具有这些附加属性:tools和allow_delegation。
大多数属性都是不言自明的,但让我们了解它们的含义。
role类似于职位,定义了代理的确切角色。例如,Agent 1角色是Topic Researchergoal告诉代理它的角色是什么rolebackstory更详细地阐述代理人的角色,使其具体化memory属性是布尔值。设置为布尔值时,True代理可以记住、推理并从过去的交互中学习。tools是代理用来执行其任务的工具列表allow_delegation是一个布尔值,告诉代理的结果是否必须委托给其他代理进行进一步处理。
现在,让我们创建每个代理。
但
在此之前,我们先设置一下第一个代理探索我的个人 YouTube 频道所需要使用的工具。
这是YouTubeChannelSearchTool通过提供句柄,使用类来实现的@techwithzoum。.
# The tool used by the topic researcher
youtube_tool = YoutubeChannelSearchTool(youtube_channel_handle='@techwithzoum')
- Agent 1 — Topic Researcher 代理 1 — 主题研究员
topic_researcher = Agent(
role='Topic Researcher',
goal='Search for relevant videos on the topic {topic} from the provided YouTube channel',
verbose=True,
memory=True,
backstory='Expert in finding and analyzing relevant content from YouTube channels, specializing in AI, Data Science, Machine Learning, and Generative AI topics.',
tools=[youtube_tool],
allow_delegation=True
)
- 我们首先将代理的角色定义为
Topic Researcher - 然后我们要求代理使用
{topic}提供的方法来查找提及该主题的相关视频。 - 最后,我们的第一个代理被定义为使用 YouTube 搜索工具查找和分析有关 AI、数据科学、机器学习和生成式 AI 主题的相关内容的专家。
当前代理的定义大体上与当前代理的定义完全相同,只是属性值有细微的变化。一旦理解了,下一个代理的定义就无需解释了。
.
2. Agent 2 — Blog Writer 代理 2 — 博客作者
blog_writer = Agent(
role='Blog Writer',
goal='Write a comprehensive blog post from the transcription provided by the Topic Researcher, covering all necessary sections',
verbose=True,
memory=True,
backstory='Experienced in creating in-depth, well-structured blog posts that explain technical concepts clearly and engage readers from introduction to conclusion.',
allow_delegation=False
)
3. Agent 3 — LinkedIn Post Creator Agent 3 — LinkedIn 帖子创建者
# LinkedIn Post Agent
linkedin_post_agent = Agent(
role='LinkedIn Post Creator',
goal='Create a concise LinkedIn post summary from the transcription provided by the Topic Researcher.',
verbose=True,
memory=True,
backstory='Expert in crafting engaging LinkedIn posts that summarize complex topics and include trending hashtags for maximum visibility.',
allow_delegation=False
)
4. Agent 4 — Twitter Post Creator Agent 4 — Twitter 帖子创建者
twitter_agent = Agent(
role='Twitter Content Creator',
goal='Create a short tweet from the transcription provided by the Topic Researcher that capture key points and insights',
verbose=True,
memory=True,
backstory='Specializes in distilling complex information into concise, impactful tweets that resonate with a tech-savvy audience.',
allow_delegation=False
)
我们注意到,最后三个代理都没有委托他们的任务。这是因为他们的结果没有被其他代理处理。
太棒了!现在我们的代理已准备好了解对他们的期望,并且通过课程来执行Task。
任务
人类在收到执行任务的指令后,就会执行运送物品的任务。
这同样适用于代理,成功执行这些任务并交付结果所需的属性如下:
description对应于对代理需要执行的操作的清晰描述。描述越清晰,模型的输出就越好expected_output是代理预期结果的文本描述agent是负责执行该特定任务的代理的占位符tools与本节中的定义类似role,并不是每个代理都会使用工具。在我们的例子中,只有Topic Researcher使用工具output_file是文件名及其格式。这仅适用于需要将任务结果生成为文件(如 markdown)的代理,在这种情况下,文件名可以blog-post.md是Blog Writer
让我们深入研究每个代理的这些任务的 Python 实现。
- Agent 1 — Topic Researcher 代理 1 — 主题研究员
research_task = Task(
description="Identify and analyze videos on the topic {topic} from the specified YouTube channel.",
expected_output="A complete word by word report on the most relevant video found on the topic {topic}.",
agent=topic_researcher,
tools=[youtube_tool]
)
2. Agent 2 — Blog Writer 代理 2 — 博客作者
blog_writing_task = Task(
description=""" Write a comprehensive blog post based on the transcription provided by the Topic Researcher.
The article must include an introduction , step-by-step guides, and conclusion.
The overall content must be about 1200 words long.""",
expected_output="A markdown-formatted of the blog",
agent=blog_writer,
output_file='./data/blog-post.md'
)
3. Agent 3 — LinkedIn Post Creator Agent 3 — LinkedIn 帖子创建者
linkedin_post_task = Task(
description="Create a LinkedIn post summarizing the key points from the transcription provided by the Topic Researcher, including relevant hashtags.",
expected_output="A markdown-formatted of the LinkedIn post",
agent=linkedin_post_agent,
output_file='./data/linkedin-post.md'
)
4. Agent 4 — Twitter Post Creator Agent 4 — Twitter 帖子创建者
twitter_task = Task(
description="Create a tweet from the transcription provided by the Topic Researcher, including relevant hastags.",
expected_output="A markdown-formatted of the Twitter post",
agent=twitter_agent,
output_file='./data/tweets.md'
)
对于每个代理来说,属性都是不言自明的,并且
- 第一个代理是后三个代理使用的原始文本数据
- 第二个代理是名为 markdown 的文件
blog-post.md - 第三个代理也是一个名为的 markdown 文件
linked-post.md - 最后一位经纪人与名字相同
tweets.mdFor each agent, the attributes are self-explanatory, and the result of the - first agent is a raw text data used by the last three agents
- second agent is markdown file called
blog-post.md - third agent is also a markdown file called
linked-post.md - last agent is the same with the name
tweets.md
Time for Agents to Get to Work 代理商开始工作的时间
最后一步是协调我们的代理作为一个团队来正确执行他们的任务,如下所示:
my_crew = Crew(
agents=[topic_researcher, linkedin_post_agent, twitter_agent, blog_writer],
tasks=[research_task, linkedin_post_task, twitter_task, blog_writing_task],
verbose=True,
process=Process.sequential,
memory=True,
cache=True,
max_rpm=100,
share_crew=True
)
agentscorresponds to the list of all our agentstasksis the list of the tasks to be performed by each agent- We set verbose to
Trueto have the full execution trace max_rpmis the maximum number of requests per minute our crew can perform to avoid rate limits- Finally,
share_crewmeans that agents are sharing resources to execute their tasks. This corresponds to the first agent sharing its response with other agents. agents对应我们所有代理商的列表tasks是每个代理要执行的任务列表- 我们将详细设置为
True获取完整的执行跟踪 max_rpm为避免速率限制,我们的团队每分钟可以执行的最大请求数是多少- 最后,
share_crew表示代理共享资源来执行任务。这对应于第一个代理与其他代理共享其响应。
在编排代理之后,是时候使用kickoff以输入字典为参数的函数来触发它们了。这里我们正在搜索我录制的关于的视频GPT3.5 Turbo Fine-tuning with Graphical Interface
After orchestrating the agents, it is time trigger them using the kickoff function which takes as parameter a dictionary of inputs. Here we are searching about a video I recorded about GPT3.5 Turbo Fine-tuning with Graphical Interface
topic_of_interest = 'GPT3.5 Turbo Fine-tuning and Graphical Interface'
result = my_crew.kickoff(inputs={'topic': topic_of_interest})
上述代码成功执行后会生成我们上面指定的所有三个 markdown 文件。
以下是显示每个文件内容的结果。作为录制视频的人,这与教程中涵盖的内容完全一致。
The successful execution of the above code generates all the three markdown files that we have specified above.
Here is the result showing the content of each file. As someone who recorded the video, that perfectly corresponds to what was covered in the tutorial.
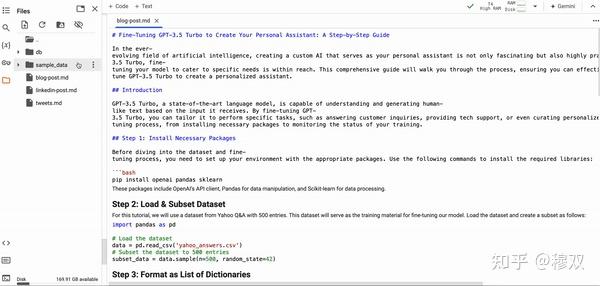
它blog agent没有提供百分之百的逐步指南来帮助用户顺利执行代码,但是它为用户提供了对教程范围的很好理解。
对于LinkedIn和Twitter帖子来说,结果是辉煌的!
您可以检查文件夹内所有文件的内容ai_agents_outputs。
信心不包括控制——评估这些代理商!
我对代理的上述评估是基于我个人对内容的熟悉程度。然而,在部署到生产环境之前,更客观、更可扩展的评估方法至关重要。
以下是一些有效评估这些人工智能代理的策略。
Benchmark testing可以用来评估每个代理在不同任务中的表现,使用已建立的数据集GLUE,并FLASK允许与不同的最先进的模型进行标准化比较。Factual Accuracy Measurement评估代理对多个领域的各种问题提供事实答案的能力。Context-Awareness Relevance Scoring可以用来量化代理响应与给定提示的匹配程度。
可以利用多个框架来执行这些评估,其中包括:
DeepEval这是一个开源工具,用于量化 LLM 在多种指标上的表现。MMLU (Massive Multitask Language Understanding)是一个在零样本和一次性设置等多种主题上测试模型的框架。OpenAI evals也是一个评估 LLM 或任何使用 LLM 构建的系统的一个框架。
结论
本文简要概述了如何利用 AI 代理有效地完成高级任务,而不是提示单个大型语言模型执行相同的任务。
The blog agent did not provide a hundred percent step-by-step guide for users to execute the code without facing an issue, but it provides a great understanding of the scope of the tutorial.
For the LinkedIn and Twitter posts, the results are brilliant!
You can check the content of all the files within theai_agents_outputs folder.
Confidence does not include control — Evaluate those agents!
My above assessment of the agents is based on my personal familiarity with the content. However, the need for a more objective and scalable evaluation methods becomes crucial before deploying into production.
Below are some strategies for efficiently evaluating those AI agents.
Benchmark testingcan be used to evaluate each agent performance across divers tasks using established datasets likeGLUE, andFLASKallowing a standardized comparisons with different state-of-the-art models.Factual Accuracy Measurementevaluates an agent’s capability to provide factual responses to a diverse range of questions across multiple domains.Context-Awareness Relevance Scoringcan be used to quantity how well the agent response align with a given prompt.
Multiple frameworks can be leveraged to perform these evaluations, and some of them include:
DeepEvalwhich is an open-source tool for quantifying LLMs’ performance across divers metrics.MMLU (Massive Multitask Language Understanding)is a framework that tests models on divers range of subjects both zero-shot and one-shot settings.OpenAI evalsis also a framework to evaluate LLMs or any system built using LLMs.
Conclusion
This article provided a brief overview how to leverage AI agents to effectively accomplish advanced tasks instead of prompting a single Large Language Model to perform the same task.
I hope this short tutorial helped you acquire new skill sets, and the complete code is available on my GitHub, and please subscribe to my YouTube to support my content.
 新公网安备 65010402001845号
新公网安备 65010402001845号